British Library Releases 1M Images into the Public Domain
Earlier this month, Open Culture pointed to a big move from the British Library: the library is putting a million images into the public domain.


One of the most beautiful aspects of the internet is how it encourages creation almost as much as it does consumption. I recently wrote about how cultural institutions are finding new ways to bring their collections to life, but access to these materials, in my opinion, is just one important step. The next is giving your visitors the opportunity to also use the materials, remix them, create new works from them.

Earlier this month, Open Culture pointed to a big move from the British Library: the library is putting a million images into the public domain. Accessible on the library’s sprawling Flickr account, these images’s copyright statuses are marked as “no known copyright restrictions.” According to Flickr Commons, this means that cultural institutions “have reasonably concluded that a photograph is free of copyright restrictions.” According to the Library’s own press release, “These images were taken from the pages of 17th, 18th and 19th century books digitised by Microsoft who then generously gifted the scanned images to us, allowing us to release them back into the Public Domain.”

A quick glance at Flickr’s Commons listings shows that the British Library joins other institutions like the Vancouver Public Library Historical Photographs, Mississippi Department of Archives and History, the Brooklyn Museum, the Library of Congress, and many more in offering their holdings to the public this way. More intriguing is something noted in the Library’s announcement:
We may know which book, volume and page an image was drawn from, but we know nothing about a given image. Consider the image below. The title of the work may suggest the thematic subject matter of any illustrations in the book, but it doesn’t suggest how colourful and arresting these images are.
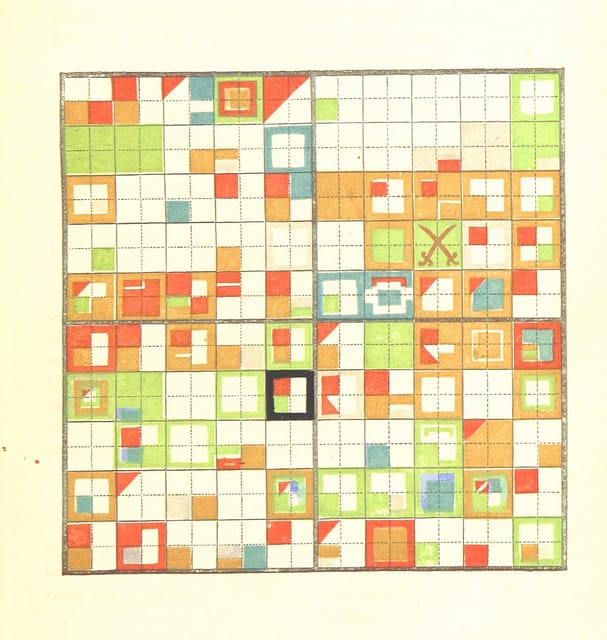
With that in mind, they plan to “launch a crowdsourcing application at the beginning of next year.” The point will be to train data for more automated classification (anyone familiar with natural language processing would be familiar with this process), but they’re also open to other suggestions. That seems to me like a great start, but I’d love to see more remixing and creative use of these images, which represent an enormous cross section of our aesthetic and visual heritage in the West. And in a clear sign of the Library’s commitment to open source and open access, they’ve placed the metadata for each image up on Github as well.




