Soon You May Be Able to Text with 2,000 Egyptian Hieroglyphs
Collaborations among Egyptologists and digital linguistics promise global visualizations of what was written on inscriptions, papyri, wall paintings, and other sources of Hieroglyphs. It may also allow for more popular knowledge of Egyptian Hieroglyphs and encourage its assimilation into popular lan

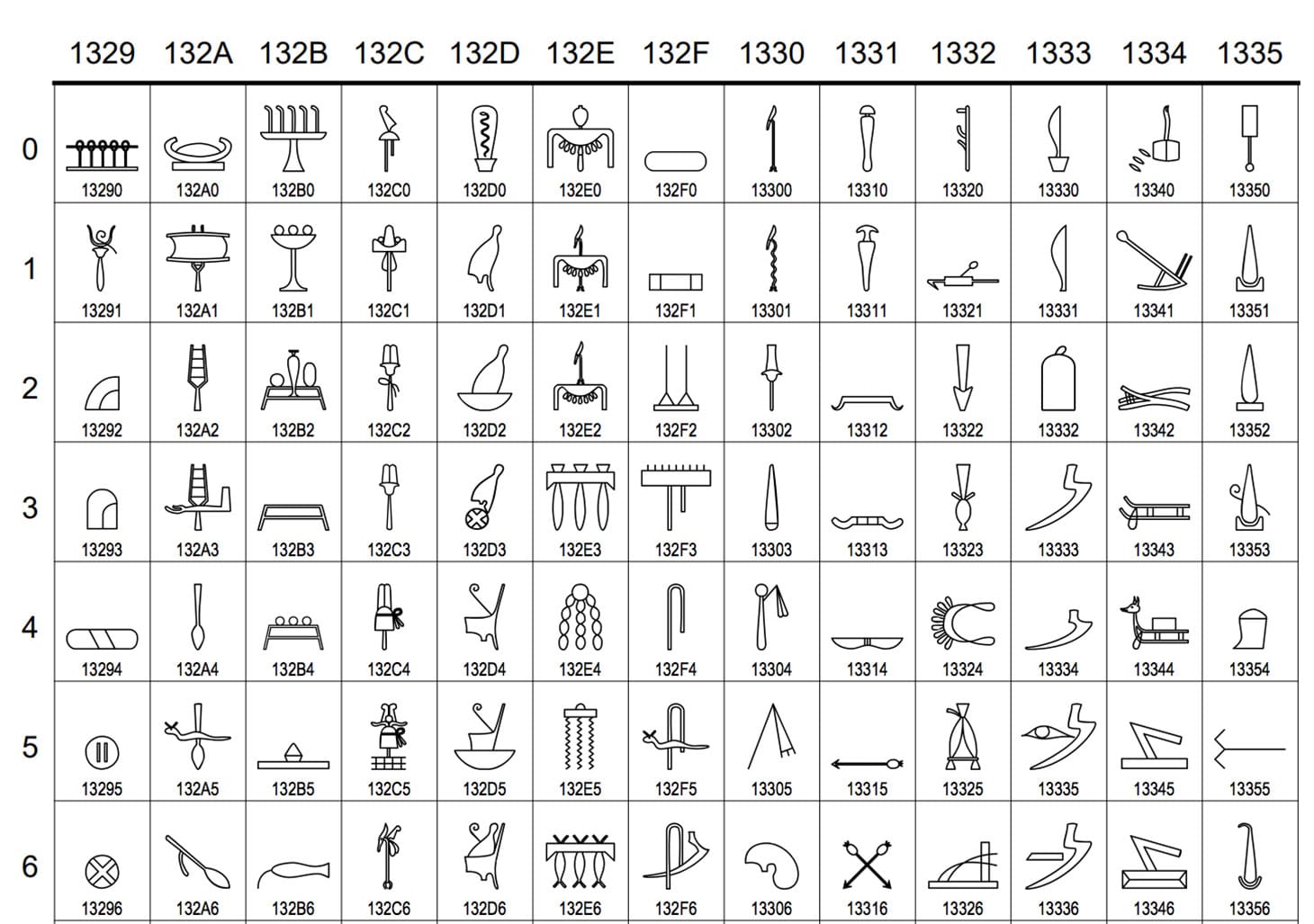
Over 2,000 new Hieroglyphs may soon be available for use on cell phones, computers, and other digital devices. The Unicode Consortium recently released a revised draft of standards for encoding Egyptian Hieroglyphs. If approved, the available Hieroglyphs will provide greater access and global uniformity for Egyptologists, covering a much longer period of Hieroglyphic usage than ever before. The proposal is part of a larger effort between the Unicode Consortium, ancient linguists, font designers, and the federal government to attempt to study, preserve, and then digitally represent ancient and endangered languages through the use of computer code.
Between 750 and 1,000 Hieroglyphs were used by Egyptian authors during the periods of the Old, Middle, and then New Kingdom (2687 BCE–1081 BCE). That number later greatly increased during the Greco-Roman period, likely to around 7,000. It was during this later time that Egypt was occupied and ruled by Alexander the Great, the Ptolemies (which included Cleopatra), and then the Roman Empire (332 BCE–641 CE). The language grew, changed, and diversified over the course of thousands of years, a fact which can now be reflected through its digital encoding. Although Egyptian Hieroglyphs have been defined within Unicode since version 5.2, released in 2009, the glyphs were highly limited in number and did not stretch into the Greco-Roman period. There was also no agreed upon method for placing hieroglyphs into groups.

Unicode first began in 1987, when Joe Becker of Xerox, along with Lee Collins and Mark Davis of Apple, set out to conjure a universal character set that could be understood across operating systems. The term itself was minted by Becker, who recognized, at the time, that there was no standardized multilingual plain text for computers. A proposal for Unicode was drafted in 1988 and the non-profit consortium was formed in 1991. These days, the Unicode board still doesn’t turn a profit. It is perhaps most famous for its standardization and encoding of emoji (v.11.0) — which can be proposed by anyone, but which are then voted upon by an official Emoji subcommittee.
As the Unicode Consortium site notes, Unicode functions successfully by assigning unique numbers to each character: “Fundamentally, computers just deal with numbers. They store letters and other characters by assigning a number for each one. Before Unicode was invented, there were hundreds of different systems, called character encodings, for assigning these numbers.” The Unicode Standard has allowed for global visualization and communication on an unprecedented scale.
The Hieroglyphic script is a challenge to encode, since it consists of logograms (signs that represent languages units), phonograms (signs that represent sounds), and determinatives (signs that join together and clarify logograms and phonograms). Those who study the ancient Mediterranean have long been dependent on font designers to design fonts for various scripts and encode ancient alphabetic characters. One of the leading ancient font designers is mathematician, computer scientist, and classicist George Douros. His earlier Aegyptus font was drawn on for the forthcoming Unicode release for Hieroglyphs.
In addition to fonts designed for Greek or Latin, the Unicode Consortium has also looked to similar languages for inspiration in drawing up the standards for the new Hieroglyphs being proposed. The release further notes: “In many aspects, this is like the work done for the Han ideographs where many ancillary data elements are associated with each Han characters (commonly known as the ‘Unihan’ database).” During China’s Han Dynasty (206 BCE–220 CE), Chinese characters were first standardized. The Unicode Consortium recognized that Chinese, Japanese and Korean (CJK) scripts have a common background connected to the Han Dynasty’s character base, one that could be standardized through Unicode.

The forthcoming release of the Hieroglyphs is actually part of a much larger consortium of typographers, digital humanists, computer scientists, and linguists. Since 2002, the Script Encoding Initiative (SEI), located at the University of California at Berkeley, had worked to preserve languages through Unicode. Deborah Anderson, a researcher in linguistics at UC-B who heads the SEI, has spearheaded the move to get more Hierogyphs into Unicode. In comments to Hyperallergic, Anderson noted the reasons for the new push: “Currently only 1071 characters are in Unicode, which limits what Egyptologists can use. This set is based on Alan Gardiner’s sign list(s). Besides the limited number of characters, Egyptologists have been restricted in how to lay out the characters with Unicode. As a result, many Egyptologists have been using software that creates images, an approach which is more limiting than Unicode characters (one can’t, for example, search for the individual characters).”

The Unicode Consortium and universities like UC-Berkeley are not the only ones who see the necessity in preserving ancient and endangered languages. Funding for the Unicode Hieroglyphs project was provided in part by the National Endowment for the Humanities (NEH), which has remained strong in the face of threats to its funding by the Trump administration. In an email to Hyperallergic, an NEH spokesperson stated that it has been the primary funder of the Script Encoding Initiative’s ‘Universal Scripts Project’ since 2005. Through five grants that total $1.3 million to the Unicode project, 70 writing systems have now been included: “from Byzantine Greek and Old Hungarian, to Javanese and Unified Canadian Aboriginal.” As the SEI and Anderson notes, there is still a great amount of work to do: “Over 100 scripts remain to be encoded. Minority scripts are still used in parts of South and Southeast Asia, Africa, and the Middle East. Unencoded scripts include Kpelle and Loma. Scripts of historical significance include Book Pahlavi, Large Khitan, and Jurchen.”
In respect to the Unicode Hieroglyphs, collaboration between active Egyptologists and digital linguists is still key to the success of preserving and encoding ancient and endangered languages. “I met last Friday with some Egyptologists to seek their feedback on a few questions, and will meet in mid-June with other Egyptologists to get their input on this document and on a few outstanding issues. Given how the standards process goes, the additional characters may not show up in Unicode until 2020 or 2021, but it should help Egyptologists out tremendously,” said Anderson. The ultimate goal is to provide Egyptologists a method for easy transmission of what was written on inscriptions, papyri, wall paintings, and other sources of Hieroglyphs. It may also allow for more popular knowledge of Egyptian Hieroglyphs and (one hopes) its assimilation into popular language-learning apps like Duolingo.
The proposed addition of Hieroglyphs demonstrates that the import of Unicode initiatives goes far beyond the standardization of amusing emoji. The encoding consortium’s efforts have been the primary way for cultures to retain some (but not all) of the aesthetics and characteristics of their language online, while also allowing for maximum operability across computers, cell phones, operating systems, and myriad digital devices. While the utopian ideal of a lingua franca spoken by all may never be a reality, perhaps the closest we have yet come is Unicode—a universal language that represents the art of the script through numbers.



